
何思玫 | 2015-08-07
kubelet作为k8s集群node上的重要组件,一直饱受关注。下面请随笔者一起walk through the code.
1. Brief introduction of kubelet
管中窥豹,可见一斑。我们首先从k8s的官方文档中对kubelet的描述中一探究竟。
The kubelet is the primary “node agent” that runs on each node. The kubelet works in terms of a PodSpec. A PodSpec is a YAML or JSON object that describes a pod. The kubelet takes a set of PodSpecs that are provided through various echanisms (primarily through the apiserver) and ensures that the containers described in those PodSpecs are running and healthy. Other than from an PodSpec from the apiserver, there are three ways that a container manifest can be provided to the Kubelet. File: Path passed as a flag on the command line. This file is rechecked every 20 seconds (configurable with a flag). HTTP endpoint: HTTP endpoint passed as a parameter on the command line. This endpoint is checked every 20 seconds (also configurable with a flag). HTTP server: The kubelet can also listen for HTTP and respond to a simple API (underspec’d currently) to submit a new manifest.
从上述描述中我们可以看到,kubelet是在集群中每个node上都必须存在的组件,负责维护管理pod。
它的工作主要基于四种source—— apiserver的PodSpec,File,HTTP endpoint及HTTP server——来更新pod。其中,File通过--file-check-frequency参数传入, HTTP通过--http-check-frequency参数。
2. Walk through the src code
文章分析的代码版本>v1.0.1, HEAD 6129d3d4。 kubelet相关代码的主入口在cmd/kublet下,调用方法的实现可能会在pkg/kubelet下。文中为了便利读者,也会就具体函数再进行标明。 下面我们就根据代码逻辑继续一次源码解读的DFS。
kubelet.go#main函数的主要流程包括如下三个步骤:
- 创建一个KubeletServer实例
- 根据命令行参数加载flag
- 启动该kubeletServer。
如下图1所示。
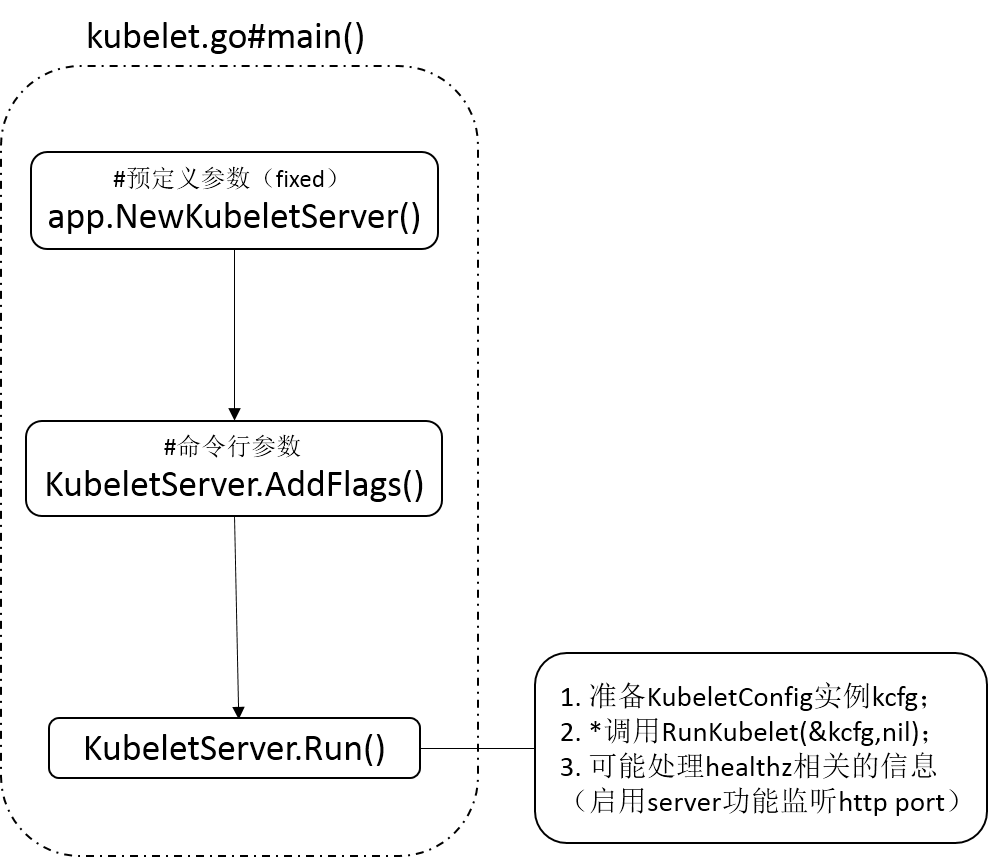
注意到,Run函数负责执行具体的kubelet的构建过程,在正常情况下是永远不会exit的。下面我们就来对该函数进行进一步的分析。
2.1 server.go#Run
如上图所示,KubeletServer.Run函数主要包括以下三个主要流程:
- 配置并构建
KubeletConfig实例。 - 调用
RunKubelet(&KubeletConfig,nil)函数真正地运行kubelet,该函数接受一个KubeletConfig类型的实例作为参数,包含了kubelet的配置信息。 - 根据
KubeletServer.HealthzPort的配置(即命令行参数--healthz-port),为/healthz url注册一个默认的handler(http.DefaultServeMux),启动health server。
可见,Run函数的核心步骤在于RunKubelet函数。
2.2 server.go#RunKubelet
我们首先通过略显复杂的图2来了解RunKubelet函数。它的使用场景非常明确,在node上创建并运行kubelet。
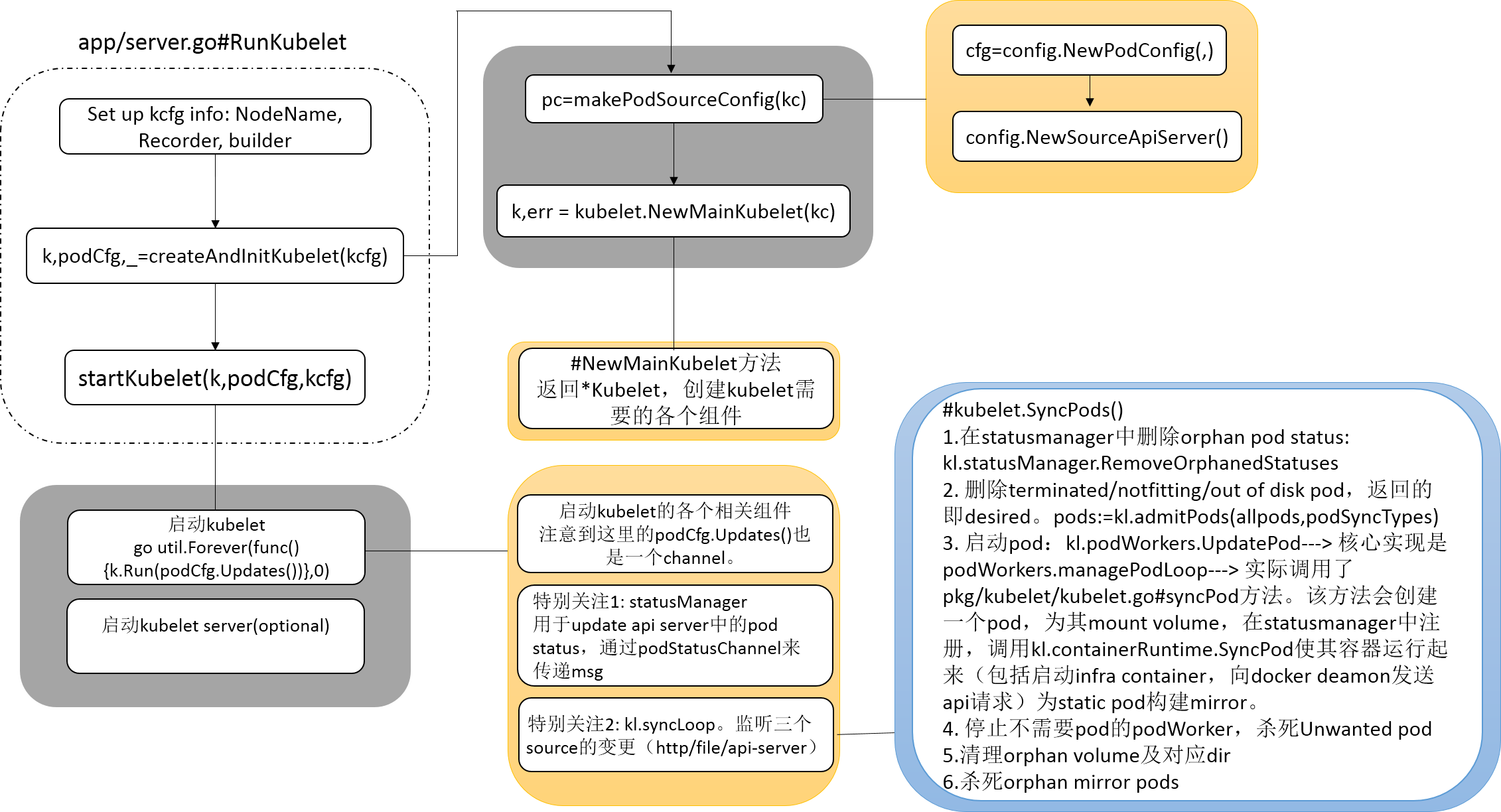
函数可以被大致划分为三大步骤。
Step1: 配置KubeletConfig信息,包括Hostname,NodeName,Recorder等。KubeletConfig这个结构包含了运行kubelet需要的所有参数,在可见的将来可能会和KubeletServer结构进行merge,不再单独存在。
- 处理Hostname/NodeName信息
- 创建了一个EventBroadcaster,创建一条包含kubelet及其NodeName配置的api.EventSource,将其注册到该EventBroadcaster中,用以记录kubelet产生的event并发送给apiserver。
- 配置capabilities:系
--allow-privileged及--HostNetworkSources参数传入的值。 - 配置使用docker拉取镜像时的credentialprovider的路径。
- 配置OSInterface信息
Step2: createAndInitKubelet,顾名思义,创建并初始化kubelet。
k, podCfg, err := builder(kcfg)builder在这里定义为createAndInitKubelet。
注意到这里返回了三个变量值,其中k为KubeletBootstrap(kubelet的interface),podCfg是config.PodConfig,最后一个是error变量。 podCfg变量是通过pc = makePodSourceConfig(kc)返回的,其中kc为传入的kubeletConfig变量。k则由NewMainKubelet函数返回。
Step3: 通过startKubelet启动kubelet,传入参数包括上一个函数的返回值及kcfg。
下面我们将就Step2和Step3进行更为详细的阐述。
2.2.1 server.go#createAndInitKubelet
这节内容主要包括两部分,首先来看makePodSourceConfig函数。
Section 1: makePodSourceConfig
该函数的返回值是一个config.PodConfig变量,用于将不同source的pod configuration合并到一个结构中,结构如下所示。
// PodConfig is a configuration mux that merges many sources of pod configuration into a single
// consistent structure, and then delivers incremental change notifications to listeners
// in order.
type PodConfig struct {
pods *podStorage //存储当前的pod state,并且保证更新到channel的updates是顺序的
mux *config.Mux //用于merge不同source的configuration
// the channel of denormalized changes passed to listeners
updates chan kubelet.PodUpdate
// contains the list of all configured sources
sourcesLock sync.Mutex
sources util.StringSet
}下面,我们具体来看makePodSourceConfig完成了什么工作。源码如下:
func makePodSourceConfig(kc *KubeletConfig) *config.PodConfig {
// source of all configuration
cfg := config.NewPodConfig(config.PodConfigNotificationSnapshotAndUpdates, kc.Recorder)
// define file config source
if kc.ConfigFile != "" {
glog.Infof("Adding manifest file: %v", kc.ConfigFile)
config.NewSourceFile(kc.ConfigFile, kc.NodeName, kc.FileCheckFrequency, cfg.Channel(kubelet.FileSource))
}
// define url config source
if kc.ManifestURL != "" {
glog.Infof("Adding manifest url %q with HTTP header %v", kc.ManifestURL, kc.ManifestURLHeader)
config.NewSourceURL(kc.ManifestURL, kc.ManifestURLHeader, kc.NodeName, kc.HTTPCheckFrequency, cfg.Channel(kubelet.HTTPSource))
}
if kc.KubeClient != nil {
glog.Infof("Watching apiserver")
config.NewSourceApiserver(kc.KubeClient, kc.NodeName, cfg.Channel(kubelet.ApiserverSource))
}
return cfg
}- 使用
NewPodConfig函数创建一个PodConfig变量cfg,用到了config.PodConfigNotificationSnapshotAndUpdates和kc.Recorder;PodConfigNotificationSnapshotAndUpdates的更新规则是,在增删pod的时候发送SET消息,其它变更发送UPDATE消息。其中,cfg.Updates是一个缓存大小为50的channel,收发数据类型为kubelet.PodUpdate(即对于某个pod的某种更新操作)。 - 向podConfig变量cfg加入config source,包括 file/hhtp(url)/apiserver source。如同在开篇综述中所说,File类型和HTTP类型的pod configuration的变更,是通过定时查询对应source完成的。
- 此处以更为常见的apiserver为例,我们使用
NewSourceApiserver监听apiserver中podSpec的变更。该函数接收三个参数,第一个参数为用于向apiserver发起请求的Client,第二个参数为NodeName,第三个参数是由cfg.Channel返回的一个只读channel,类型是chan <- interface{}。
也许读者会好奇,这个Channel函数具体做了哪些工作呢? 它会创建并返回一个interface{}类型的channel,并且启动go routine持续监听该Channel,并且将监听到的update进行merge。
merge是在NewPodConfig阶段决定的,即此前newPodStorage(updates, mode, recorder)返回的podStorage的Merge函数。该Merge函数定义在pkg/kubelet/config/config.go中,在该过程中会将监听的channel中更新的信息更新到cfg.updates中。限于篇幅,此处只展示PodConfigNotificationSnapshotAndUpdates对应的case,其它仅以”…“代替。
// Merge normalizes a set of incoming changes from different sources into a map of all Pods
// and ensures that redundant changes are filtered out, and then pushes zero or more minimal
// updates onto the update channel. Ensures that updates are delivered in order.
func (s *podStorage) Merge(source string, change interface{}) error {
s.updateLock.Lock()
defer s.updateLock.Unlock()
adds, updates, deletes := s.merge(source, change)//负责merge变更并且filter out冗余
// deliver update notifications:根据不同mode分发update notification
switch s.mode {
...
case PodConfigNotificationSnapshotAndUpdates:
if len(updates.Pods) > 0 {
s.updates <- *updates //变更OP为UPDATE
}
if len(deletes.Pods) > 0 || len(adds.Pods) > 0 {
s.updates <- kubelet.PodUpdate{s.MergedState().([]*api.Pod), kubelet.SET, source}
}//ADD与REMOVE的OP为SET
...
}
return nil
}也就是说,cfg.Channel返回的是一个未知具体类型的被持续监听的channel(且该channel在merge之后会影响到原cfg),那么写channel的工作由谁完成呢?我们相信这是由config source(此处即apiserver)来完成的,也会在NewSourceApiserver函数分析中进行阐释。
通过
NewListWatchFromClient函数构造了一个ListWatch调用
newSourceApiserverFromLW来watch并pull(拉取)apiserver的更新。// newSourceApiserverFromLW holds creates a config source that watches and pulls from the apiserver. func newSourceApiserverFromLW(lw cache.ListerWatcher, updates chan<- interface{}) { send := func(objs []interface{}) { var pods []_api.Pod for _, o := range objs { pods = append(pods, o.(_api.Pod)) } updates <- kubelet.PodUpdate{ pods, kubelet.SET, kubelet.ApiserverSource } } cache.NewReflector(lw, &api.Pod{}, cache.NewUndeltaStore(send, cache.MetaNamespaceKeyFunc), 0).Run() }
可以看到,newSourceApiserverFromLW的执行核心只有一行代码,将创建出来的Reflector Run起来。
NewReflector函数创建一个Reflector对象,用于保证传入的第三个参数Store里的内容是update to date的。第三个参数以send函数为参数构建一个UndeltaStore,其PushFunc为send函数。 UndeltaStore listens to incremental updates and sends complete state on every change.也就是说,UndeltaStore不仅接受从Reflector来的update,并且还会使用UndeltaStore.PushFunc来进行change的deliver。这里就是写入到Cfg.Updates里,即完成了update的写操作。
// Reflector watches a specified resource and causes all changes to be reflected in the given store.
type Reflector struct {
// name identifies this reflector. By default it will be a file:line if possible.
name string
// The type of object we expect to place in the store
//Store中存储的object类型
expectedType reflect.Type
// The destination to sync up with the watch source
// 即要与source更新保持同步的object存储的位置,理解为local caching system;Store是一个interface,在本例中UndeltaStore是Store的一个实现。
store Store
// listerWatcher is used to perform lists and watches.
listerWatcher ListerWatcher
// period controls timing between one watch ending and
// the beginning of the next one.
period time.Duration
resyncPeriod time.Duration
// lastSyncResourceVersion is the resource version token last
// observed when doing a sync with the underlying store
// it is thread safe, but not synchronized with the underlying store
lastSyncResourceVersion string
// lastSyncResourceVersionMutex guards read/write access to lastSyncResourceVersion
lastSyncResourceVersionMutex sync.RWMutex
}Note:之前在集群运行过程中遇到过一个error,(可能在将来会upgrage成warning),即watcher超时,导致kubelet报错,位于reflector.go line#225。更新的内容来自listWatch,即apiserver。这里相当于是写updates。
Section 2: NewMainKubelet
我们通过pkg/kubelet/kubelet.go#NewMainKubelet函数构造了一个Kubelet。在该函数中创建各个kubelet需要的组件,部分参见如下列表
- ContainerGC manages garbage collection of dead containers。负责进行对死掉的container进行垃圾回收。
- ImageManager manages lifecycle of all images. 负责管理image。
- DiskSpaceManager manages policy for diskspace management for disks holding docker images and root fs. 负责进行磁盘管理。
- StatusManager updates pod statuses in apiserver. Writes only when new status has changed.该结构体中的
podStatusChannel负责buffer podStatusSyncRequest,是一个缓冲区大小为1000的channel。 从apiserver中更新pod状态。 - ReadinessManager maintains the readiness information(probe results) of containers over time to allow for implementation of health thresholds.负责收集container的readiness information(readiness info具体指什么并不明晰,是一个bool型,可能代表该container是否准备好?)。
- RefManager manages the references for the containers. The references are used for reporting events such as creation, failure, etc.
- VolumeManager manages the volumes for the pods running on the kubelet. Currently it only does book keeping, but it can be expanded to take care of the volumePlugins.
- OOMWatcher watches cadvisor for system oom’s and records an event for every system oom encountered.
- 初始化network plugin。这是个alpha feature。
- ContainerRuntime 可以是DockerManager或者是rkt,默认为docker。
- ContainerManager manages the containers running on a machine. -(周期性)配置网络参数(iptables rules)。 -(周期性)向master节点发送其它各个node的状态。synchronizes node status to master, registering the kubelet first if necessary.
- 启动ContainerRuntime。ContainerRuntime是Runtime(interface)的一个实现,定义在pkg/kubelet/container/runtime.go中,包含了
SyncPod/GetPodStatus等重要方法。以”docker”为例,它将是一个DockerManager,定义在pkg/kubelet/dockertools/manager.go中,并且实现了Runtime的所有方法。 - PodManager stores and manages access to the pods. Kubelet discovers pod updates from 3 sources: file, http, and apiserver.三个update pod的来源,均在上例中的
makePodSourceConfig中进行了注册。 特别地,对于非apiserver来源的pod,apiserver是不知道其变更的。为了对其进行更新,我们创建了static pod。A mirror pod has the same pod full name (name and namespace) as its static counterpart (albeit different metadata such as UID, etc). By leveraging the fact that kubelet reports the pod status using the pod full name, the status of the mirror pod always reflects the actual status of the static pod. When a static pod gets deleted, the associated orphaned mirror pod will also be removed. 根据GetPodByFullName的原则,mirror pod会映射原pod的状态。 - 为containerRuntime设置RuntimeCache。RuntimeCache caches a list of pods.该Cache中pod的状态会通过它的两个方法
GetPods和ForceUpdateIfOlder来更新。 - 创建PodWorkers。
klet.podWorkers = newPodWorkers(runtimeCache, klet.syncPod, recorder)第二个参数将作为podWorker.syncPodFn,即用以sync the desired stated of pod.实现为‵func (kl *Kubelet) syncPod`(定义在pkg/kubelet/kubelet.go)。 - 在metrics中注册RuntimeCache。 创建目录,默认根目录在/var/lib/kubelet下,并在根目录下创建pods目录和plugins目录。
- 初始化所有注册的(即可以访问kubelet的)plugin。
- 建立记录容器的log目录(/var/log/containers)。
至此,所有相关组件或目录文件都已经被创建完毕,该函数返回一个Kubelet实例。
2.2.2 startKubelet
如果读者还记得我们在2.2节中的下段描述,“Step 3: 通过startKubelet启动kubelet,传入参数包括上一个函数的返回值及kcfg。” 那将是一个莫大的幸事,因为我们终于要从一个非常深的源码栈中跳出进入另一个更深的栈了:) 创建完毕kubelet的,下边无疑要进行的是运行操作。
根据运行类别分为两种,其一为RunOnce(只运行一次),其二为startKubelet(持续运行不退出);两种情况本质的处理逻辑是类似的,下面谨以第二种为例进行讲述。
该函数的核心——启动kubelet——由如下一行代码完成,
go util.Forever(func() { k.Run(podCfg.Updates()) }, 0)podCfg.Updates()返回podCfg.updates,类型为<-chan kubelet.PodUpdate,即前述提及的缓冲区为50的用以存储Pod更新信息的channel,让我们来一览其结构。
// PodUpdate defines an operation sent on the channel. You can add or remove single services by
// sending an array of size one and Op == ADD|REMOVE (with REMOVE, only the ID is required).
// For setting the state of the system to a given state for this source configuration, set
// Pods as desired and Op to SET, which will reset the system state to that specified in this
// operation for this source channel. To remove all pods, set Pods to empty object and Op to SET.
//
// Additionally, Pods should never be nil - it should always point to an empty slice. While
// functionally similar, this helps our unit tests properly check that the correct PodUpdates
// are generated.
type PodUpdate struct {
Pods []*api.Pod
Op PodOperation
Source string
}Kubelet.Run()定义在pkg/kubelet/kubelet.go中,它完成的工作包括
- 定义kubelet.logServer
- 如果kl.resourceContainer不为空(命令行参数
--resource-container,”Absolute name of the resource-only container to create and run the Kubelet in (Default: “/kubelet.”) ),则将kubelet移入该container中。 - 启动imageManager。运行时该imageManager负责持续list image和container,并在其Record中更新。
- 启动cadvisor。
- 启动containerManager。
- 启动oomWatcher。
- 启动周期性更新uptime。
- 启动statusManager。
- syncLoop(updates, kl)。
statusManager.Start和syncLoop具体做了什么工作,可能会引起读者的兴趣。下面我们就具体进行分析。为了让结构显得更为明晰,我们还是新起一个小章节:)
2.2.2.1 statusManager的启动
我们知道statusManager负责监听从apiserver对于pod的更新,更新的读写通过podStatusSyncRequest类型的channelpodStatusChannel。
type podStatusSyncRequest struct {
pod *api.Pod
status api.PodStatus
}
// Updates pod statuses in apiserver. Writes only when new status has changed.
// All methods are thread-safe.
type statusManager struct {
kubeClient client.Interface
// Map from pod full name to sync status of the corresponding pod.
podStatusesLock sync.RWMutex
podStatuses map[string]api.PodStatus
podStatusChannel chan podStatusSyncRequest
}statusManager.Start执行核心工作的代码如下
go util.Forever(func() {
err := s.syncBatch()
if err != nil {
glog.Warningf("Failed to updated pod status: %v", err)
}
}, 0)即持续运行s.syncBatch(),这个函数负责同apiserver交互来获得pod status的更新(located @pkg/kubelet/status_manager.go),在没有更新时会block。这是因为在该函数中会等待s.podStatusChannel的返回值。从另一个角度而言,这是在读channel,写channel的操作应该由apiserver完成。
2.2.2.2 syncLoop
syncLoop这个函数使用到了传入的channel参数,即podCfg.updates,第二个参数为kubelet实例本身。它的函数体异常简单,但是却为我们执行了非常重要的sync pod的核心任务。
// syncLoop is the main loop for processing changes. It watches for changes from
// three channels (file, apiserver, and http) and creates a union of them. For
// any new change seen, will run a sync against desired state and running state. If
// no changes are seen to the configuration, will synchronize the last known desired
// state every sync_frequency seconds. Never returns.
func (kl *Kubelet) syncLoop(updates <-chan PodUpdate, handler SyncHandler) {
glog.Info("Starting kubelet main sync loop.")
for {
kl.syncLoopIteration(updates, handler)
}
}syncLoopIteration方法在检查各种配置之后,启动select监听updates(channel)上的数据,一旦有更新的数据,则执行podManager.UpdatePods方法,负责update the internal pods with those provided by the update,实际上就是在podManager的列表里进行相应的更新,并进行相应的标记——把每个pod(以types.UID标记)及其SyncPodType记录好(该函数执行完毕后,所有现有的pod的状态都是”sync”)。
podSyncTypes := make(map[types.UID]SyncPodType)
kl.podManager.UpdatePods(u, podSyncTypes)然后,则是最为重要的sync pod
if err := handler.SyncPods(pods, podSyncTypes, mirrorPods, start); err != nil {
glog.Errorf("Couldn't sync containers: %v", err)
}handler.SyncPods方法实际为pkg/kubelet/kubelet.go#SyncPods,进行的工作为SyncPods synchronizes the configured list of pods (desired state) with the host current state。具体包括如下步骤:
- 根据传入的现存pod列表将statusManager中的不存在的pod entry删除。
- 通过
admitPods函数过滤terminated& notfitting & outofdisk pods,返回的pod列表即为desired pod。 - 对照desired pod列表,进行sync工作,具体是由
Kubelet.podWorkers.UpdatePod来完成的。 - 把不存在的pod对应的podWorkers释放掉。这里就体现了维护
podWorkers.podUpdates这个field的重要性。 - 杀死不需要的pod。
- 杀死孤儿volume。
- 删除不存在的pod对应的dir
- 删除孤儿mirror pod
下面我们来具体分析一下第3条Kubelet.podWorkers.UpdatePod进行的工作。
// Apply the new setting to the specified pod. updateComplete is called when the update is completed.
func (p *podWorkers) UpdatePod(pod *api.Pod, mirrorPod *api.Pod, updateComplete func()) {
uid := pod.UID
var podUpdates chan workUpdate
var exists bool
updateType := SyncPodUpdate
p.podLock.Lock()
defer p.podLock.Unlock()
if podUpdates, exists = p.podUpdates[uid]; !exists {
podUpdates = make(chan workUpdate, 1)
p.podUpdates[uid] = podUpdates
updateType = SyncPodCreate
go func() {
defer util.HandleCrash()
p.managePodLoop(podUpdates) // 创建一个新的pod
}()
}
if !p.isWorking[pod.UID] {
p.isWorking[pod.UID] = true
podUpdates <- workUpdate{
pod: pod,
mirrorPod: mirrorPod,
updateCompleteFn: updateComplete,
updateType: updateType,
}
} else {
p.lastUndeliveredWorkUpdate[pod.UID] = workUpdate{
pod: pod,
mirrorPod: mirrorPod,
updateCompleteFn: updateComplete,
updateType: updateType,
}
}
}如果该pod在podWorkers.podUpdates里不存在,则需要进行创建,此时调用podWorkers.managePodLoop。 然后,根据podWorkers.isWorking[pod.UID]的值更新对应podUpdates的值或者传入podWorkers.lastUndeliveredWorkUpdate。这是对于对应pod状态的一个记录。
下面我们具体来看一下创建新pod的过程经历了什么。
func (p *podWorkers) managePodLoop(podUpdates <-chan workUpdate) {
var minRuntimeCacheTime time.Time
for newWork := range podUpdates {
func() {
defer p.checkForUpdates(newWork.pod.UID, newWork.updateCompleteFn)
//更新runtimeCache
if err := p.runtimeCache.ForceUpdateIfOlder(minRuntimeCacheTime); err != nil {
glog.Errorf("Error updating the container runtime cache: %v", err)
return
}
//获得所有pods
pods, err := p.runtimeCache.GetPods()
if err != nil {
glog.Errorf("Error getting pods while syncing pod: %v", err)
return
}
//sync pod(依次进行)
err = p.syncPodFn(newWork.pod, newWork.mirrorPod,
kubecontainer.Pods(pods).FindPodByID(newWork.pod.UID), newWork.updateType)
if err != nil {
glog.Errorf("Error syncing pod %s, skipping: %v", newWork.pod.UID, err)
p.recorder.Eventf(newWork.pod, "failedSync", "Error syncing pod, skipping: %v", err)
return
}
minRuntimeCacheTime = time.Now()
newWork.updateCompleteFn()
}()
}
}从代码中可以看到,核心步骤调用了podWorkers.syncPodFn,这是在创建podWorker时构建的,具体指向了func (kl *Kubelet) syncPod(定义在pkg/kubelet/kubelet.go,完整的传参列表
func (kl *Kubelet) syncPod(pod *api.Pod, mirrorPod *api.Pod, runningPod kubecontainer.Pod, updateType SyncPodType) error {}这个函数在做什么呢? Let’s figure it out.
canRunPod:确认是否有足够的权限运行该pod。- 创建pod data存储的目录,包括root目录(以pod的UID命名)/volumes/plugins(默认在/var/lib/kubelet/pods下)
- 为pod创建reference
- mount volume,并且在volumeManager中设置相应的entry。volume是pod的manifest里边的Spec.Volumes下的信息。
- 更新statusManager中的pod信息。根据传入参数updateType的不同,a)对于create:
kl.statusManager.SetPodStatus(pod, podStatus),在statusManager里为新的pod设置StartTime,并且将新的podStatusSyncRequest传给statusManager.podStatusChannel。b)否则,通过kl.containerRuntime.GetPodStatus(pod)获得pod信息(返回值是api.PodStatus )。但是,在现在这个context中,应该为a). - 获得inspect pod的manifest中pod.Spec.ImagePullSecrets的信息。(这个secret是用来pull image的)
- sync pod(在下文中再进行详细论述)
- 根据该pod是否为static pod,在podManager中进行了相应的设置。
sync pod的过程,以DockerManager.SyncPod为例。有鉴于函数体比较长,在此就不再贴出源码。其功能非常明晰——目的在于使得running pod能够match对应的desired pod。
- 计算running pod和desired pod之前的差距,返回的信息里包括StartInfraContainer(是否需要创建infra container),InfraContainerId(infra container ID),ContainersToStart(需要start的container),ContainersToKeep(需要keep的container)。
- 根据返回的信息决定是否重启infra container((即gcr.io/google_containers/pause:0.8.0),配置network及其它container
至此,Kubelet.syncLoopIteration算是基本完成了。这也就意味着kubelet已经在node上运行起来,充当其pod的维护者的角色了。
3. Summary
总之,从宏观角度上而言,kubelet进行的工作就是从apiserver/file/http中获取pod更新的信息,并且定期进行sync pod。其中有大量的工作都涉及了channel的使用,也希望读者在阅读的过程中能够加以注意。