
丁轶群 | 2014-04-15
在Cloud Foundry v2版本中,Health_Manager_next已经替代v1版本中的Health_Manager。
笔者写这篇文档之前,在Github上,Health_Manager_next作为一个单独的项目,存在于Cloud Foundry之下;然而在笔者写这篇文档的时候,Health_Manager_next项目在Cloud Foundry下已经不复存在,然而进入原先的Health_Manager项目,可以发现,Health_Manager项目的项目说明已经成为HealthManager 2.0,因此可见之前的Health_Manager_next项目,也就是HealthManager 2.0如今改名为Health_Manager项目,并覆盖Cloud Foundry v1版本的Health_Manager项目。下文对于该部分的称呼全部使用Health_Manager,而非之前的Health_Manager_next。
1. Health_Manager概述
在Cloud Foundry中,Health_Manager主要负责监控应用的状态,并且保证应该在DEA中运行的应用的确在运行,还有这些应用的实例数量,实例版本都符合预期的状况。
在实现过程中,Health_Manager会拥有两份数据,一份是DEA中运行应用的实际状态,另一份是Cloud Foundry对应用运行的状态预期。Health_Manager将这两份数据进行对比,对于一个应用来讲,当它的两份数据没有差异时,则说明该应用处于健康状态,不需要Cloud Controller对此做出管理措施;当它的两份数据出现差异时,则说明该应用处于非预期状态,因此Health_Manager需要分析差异,得到结果后,通知Cloud Controller做出相应的管理措施。
2. Health_Manager组件对外接口实现
Health_Manager作为Cloud Foundry的一个组件,需要和Cloud Foundry其他的组件进行通信。其中Health_Manager组件与DEA组件和Cloud Controller组件建立通信。
2.1. Health_Manager组件对DEA组件的接口实现
由于Health_Manager主要负责监控DEA中应用的状态,因此Health_Manager必须与DEA进行通信,从而获取应用的实际运行状态。
Health_Manager组件与DEA组件的通信,通过Cloud Foundry的消息中间件NATS来实现,实现方式为“订阅/发布消息”。由于Health_Manager只从DEA组件获取信息,而DEA不会向Health_Manager组件获取信息,因此在实现过程中,Health_Manager都是订阅了若干主题的消息,通过DEA发布相应主题的消息来实现信息的获取。
Health_Manager组件对DEA组件的接口代码实现,主要在/health_manager/lib/health_manager/actual_state.rb中的start方法中:
def start
logger.info "hm.actual-state.subscribing"
@message_bus.subscribe('dea.heartbeat') do |message|
process_heartbeat(message)
end
@message_bus.subscribe('droplet.exited') do |message|
process_droplet_exited(message)
end
@message_bus.subscribe('droplet.updated') do |message|
process_droplet_updated(message)
end
end2.2. Health_Manager组件对Cloud Controller组件的接口实现
Health_Manager会DEA中应用运行的实际状态和相应应用的预期状态进行比较,而相应应用的预期状态,来自Cloud Controller。关于这些预期的状态,包括应用的运行情况为运行还是停止;对于一个应用而言,应该有多少个应用实例在运行等。
Health_Manager可以通过基于HTTP请求的BULK API向Cloud Controller获取。 BULK API包含了Cloud Controller认为应用应该运行的状态。这些应用的状态信息主要是Cloud Controller的数据库CCDB中数据的一个副本。可以想象的是,这些数据可能会和DEA中应用运行的真实情况有所差异。而Health_Manager就是需要解决这个不一致问题。
Health_Manager除了会向Cloud Controller发送HTTP请求之后,也会订阅一些主题的消息,Cloud Controller正是通过这些主题的消息,获取Health_Manager的信息,比如应用用户需要获取应用实时的状态信息,则Cloud Controller通过NATS向Health_Manager发送消息,Health_Manager响应该消息。
3. Health_Manager组件内模块实现
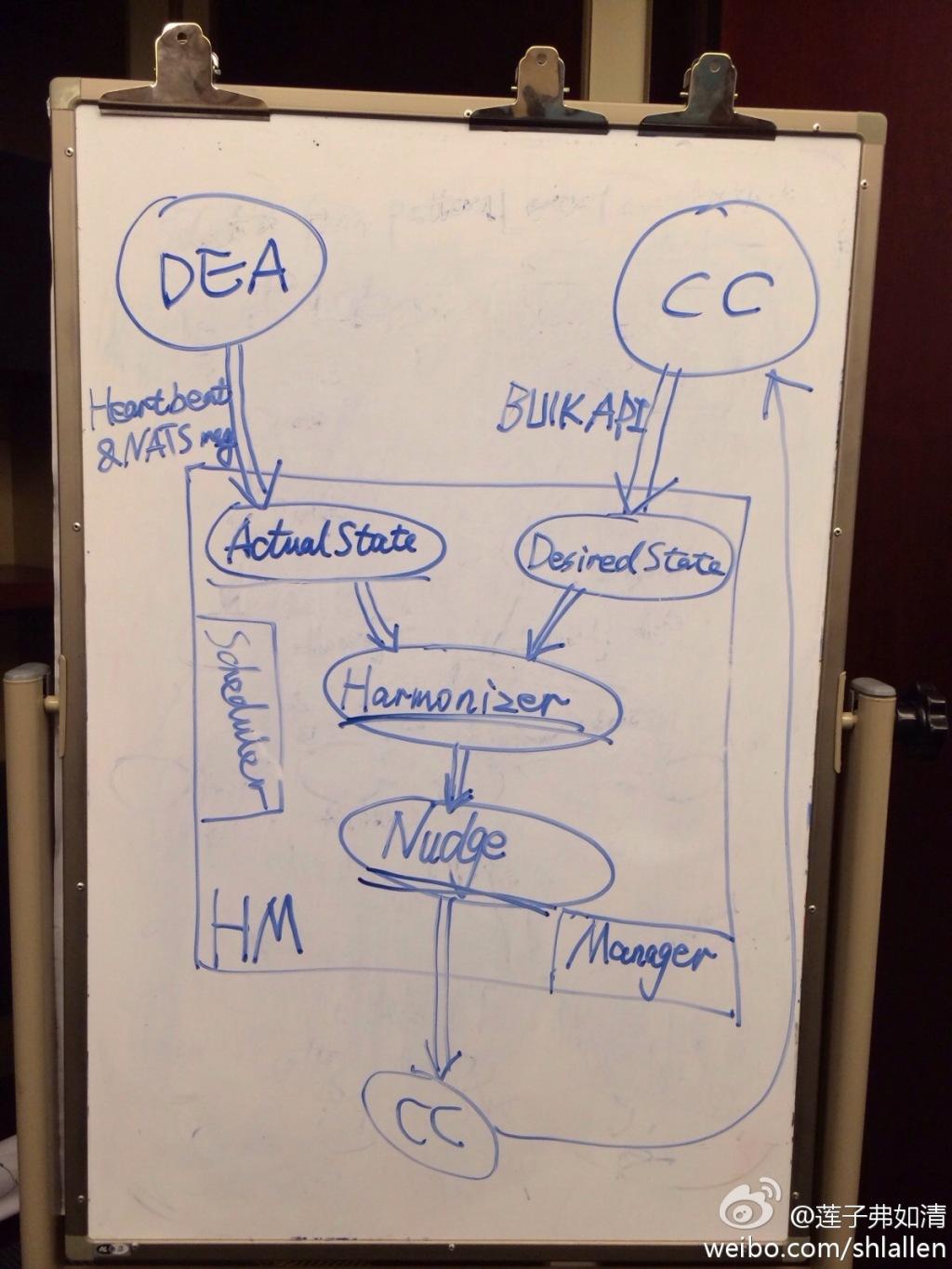
通过研究Health_Manager该项目的源码实现,可以清楚的发现Health_Manager内部的结构非常清晰,主要有Manager,Harmonizer,Scheduler,DesiredState,ActualState,Nudger和Reporter。
以下对各个模块进行简单介绍:
Manager
提供整个Health_Manager项目的执行入口,提供配置初始化,实现Health_Manager组件内其它模块的初始化,以及将注册Health_Manager组件。
Harmonizer
通过分析ActualState,得出如何将应用变成DisiredState的策略。 在Harmonizer中,ActualState与DesiredState会定期进行比较,实现通过Scheduler。
Scheduler
模拟了EventMachine的功能,用于时钟设置与取消等。
DesireState
提供应用预期的运行的状态。
ActualState
提供应用在DEA中的实际状态,这部分状态信息主要来源于ActualState模块监听DEA向Health_Manager发送来的心跳信息以及其他应用停止等消息。在实现过程中,每一个应用的状态都用一个AppState对象表示。这个对象在获取DEA第一次发送来心跳信息是被建立,从而该对象的信息会被更新。
Nudger
提供接口使得Health_Manager可以改变DEA中应用的运行状态,实现方法为分发请求给Cloud Controller,由Cloud Controller来具体执行改变DEA中应用的运行状态。实现途径中,Nudger维护了一个请求队列,通过对队列的管理来实现不同优先级请求的分发。
以下是Health_Manager结合自身内部各模块的示意图:
3.1. Manager模块源码实现
Manager是整个Health_Manager的运行入口,同时也负责其他模块的初始化以及运行。 首先来看Manager模块的start方法实现,如下:
def start
logger.info("starting...")
EM.epoll
EM.run do
message_bus = CfMessageBus::MessageBus.new(uri: message_bus_uri, logger: logger)
setup_components(message_bus)
@reporter.prepare
@harmonizer.prepare
@actual_state.start
register_as_vcap_component(message_bus)
@scheduler.start #blocking call
end
end在该方法中,通过运行EventMachine来实现,创建与消息中间件NATS的连接,以及通过该连接对象实现其他模块的设置与创建,随后又对这些模块发起运行命令。以下着重进入setup_component方法:
def setup_components(message_bus)
if HealthManager::Config.black_box_test_mode?
@scheduler = FakeScheduler.new(message_bus)
@@scheduler = @scheduler
else
@scheduler = Scheduler.new
end
@droplet_registry = DropletRegistry.new
@actual_state = ActualState.new(@varz, @droplet_registry, message_bus)
@desired_state = DesiredState.new(@varz, @droplet_registry, message_bus)
@nudger = Nudger.new(@varz, message_bus)
@harmonizer = Harmonizer.new(@varz, @nudger, @scheduler, @actual_state, @desired_state, @droplet_registry)
@reporter = Reporter.new(@varz, @droplet_registry, message_bus)
end在该方法中,Manager模块创建了多个其他模块,比如droplet_registry,actual_state,desired_state,nudger,harmonizer,reporter等。
在Manager的start方法中,调用了setup_component方法之后,又调用了多个模块的运行方法,使得这些模块真正运行起来,如:
@reporter.prepare
@harmonizer.prepare
@actual_state.start
register_as_vcap_component(message_bus)
@scheduler.start #blocking call在Manager模块执行完start方法后,Health_Manager的其他模块也就开始执行了,以下进入其他模块进行简单分析。
3.2. ActualState模块源码实现
ActualState模块的功能上文已经讲述,现在进入该模块的代码实现。
ActualState的创建由Manager模块的setup_component方法来实现:
@actual_state = ActualState.new(@varz, @droplet_registry, message_bus)而该@actual_state对象的运行在Manager的start方法中:
def start
logger.info("starting...")
EM.epoll
EM.run do
message_bus = CfMessageBus::MessageBus.new(uri: message_bus_uri, logger: logger)
setup_components(message_bus)
@reporter.prepare
@harmonizer.prepare
@actual_state.start
register_as_vcap_component(message_bus)
@scheduler.start #blocking call
end
end首先进入该模块的订阅消息部分:
def start
logger.info "hm.actual-state.subscribing"
@message_bus.subscribe('dea.heartbeat') do |message|
process_heartbeat(message)
end
@message_bus.subscribe('droplet.exited') do |message|
process_droplet_exited(message)
end
@message_bus.subscribe('droplet.updated') do |message|
process_droplet_updated(message)
endend
深入了解这部分的代码之后,可以发现,ActualState信息的获取,就是通过订阅这三个主题的消息得到的。’dea.heartbeat’代表DEA发送给Health_Manager的心跳信息的主题;’droplet.exit’代表DEA中有应用退出时发送给Health_Manager关于应用的退出消息的主题;’droplet.update’代表当应用有信息被更新的主题。
首先进入process_heartbeat方法中,当有DEA组件发布’dea.heartbeat’消息时,ActualState模块随即获取消息的message,对其执行process_heartbeat方法,方法实现如下:
def process_heartbeat(message)
logger.debug "hm.actual-state.process-heartbeat",
:dea => message.fetch(:dea)
varz[:heartbeat_msgs_received] += 1
message[:droplets].each do |beat|
droplet = get_droplet(beat)
droplet.process_heartbeat(Heartbeat.new(beat))
harmonizer.on_extra_instances(droplet, droplet.extra_instances)
end
end首先ActualState将message中的droplets信息全部取出,针对每一个droplet的心跳信息,通过 droplet = get_droplet(beat) ,将droplet信息保存。随后对于该droplet对象执行process_heartbeat方法,实现对droplet对象的简单处理,包括处理得到该对象的extra_instance对象,最后通过harmonizer来实现对应用多余的instance删除的操作。
以下进入process_droplet_exit方法,可以知道该方法是在有应用需要退出的时候被调用,现在进入源码分析:
def process_droplet_exited(message)
logger.debug "hm.actual-state.process-droplet-exited",
:message => message
varz[:droplet_exited_msgs_received] += 1
droplet = get_droplet(message)
droplet.mark_instance_as_down(message.fetch(:version),
message.fetch(:index),
message.fetch(:instance))
case message.fetch(:reason)
when CRASHED
varz[:crashed_instances] += 1
droplet.process_exit_crash(message)
harmonizer.on_exit_crashed(droplet, message)
when DEA_SHUTDOWN, DEA_EVACUATION
droplet.reset_missing_indices
harmonizer.on_exit_dea(droplet, message)
when STOPPED
droplet.reset_missing_indices
harmonizer.on_exit_stopped(message)
end
end在源码实现中,可以看到,通过分析message中:reason属性的值,来引导下一步的操作。 当应用退出的原因为CRASHED的话,那么对于该应用,首先修改该应用的状态,然后通过harmonizer对象来执行相应的crashed退出操作。
当应用退出的原因是DEA_SHUTDOWN或者DEA_EVACUATION时,则说明这些应用退出是因为原先这些应用所在的DEA组件退出了,而Cloud Foundry对于这种状况,采取的措施为重新寻找合适的DEA来运行先前的那些应用,在代码中,也是首先先设置不再运行的那些应用实例的分片,然后再通过harmonizer对该应用执行DEA退出的操作。
当应用实例退出的原因为STOPPED的话,也就是说应用实例有可能被用户主动叫停,那么首先先将这些应用实例的状态在分片中设置,然后再通过harmonizer对该应用执行应用实例被停止的操作。
以下进入process_droplet_updated方法,可以知道该方法是在有应用实例被更新的时候被调用,现在进入源码分析:
def process_droplet_updated(message)
logger.debug "hm.actual-state.process-droplet-updated",
:droplet => message.fetch(:droplet)
varz[:droplet_updated_msgs_received] += 1
droplet = get_droplet(message)
droplet.reset_missing_indices
harmonizer.on_droplet_updated(droplet, message)
end在源码实现中,可见首先是通过message来定位到相应的droplet对象,然后通过harmonizer对象对该droplet对象进行更新操作,具体实现在Harmonizer模块讲述。
3.3. DesiredState模块源码实现
DesiredState模块最主要的功能是,从Cloud Controller获取应用所预期的运行状态,该部分信息为CCDB的一个副本。DesiredState通过BULK API向Cloud Controller发送HTTP请求。
DesireState的创建由Manager模块的setup_component方法来实现:
@desired_state = DesiredState.new(@varz, @droplet_registry, message_bus)而该@desired_state对象的运行在@harmonizer中,因为在创建@harmonizer对象时,Manager将很多对象都进行传递,如下:
@harmonizer = Harmonizer.new(@varz, @nudger, @scheduler, @actual_state, @desired_state, @droplet_registry)而在@harmonizer的运行过程中,对DesiredState对象进行周期性调度,于lib/health_manager/harmonizer.rb,如下:
scheduler.at_interval :desired_state_update do
update_desired_state
end而update_desired_state方法实现为:
def update_desired_state
desired_state.update_user_counts
varz.reset_desired!
desired_state.update
end进入DesiredState模块,即lib/health_manager/desired_state.rb中,首先来到update_user_counts方法。在该方法中,DesiredState先调用with_credentials方法通过Cloud Controller的BULK API向Cloud Controller获取关于用户的credentials信息;随后通过这些credentials信息再次构建HTTP请求,再向Cloud Controller发送,获取用户数。
在desired_state.update实现中,调用process_next_batch方法,于lib/health_manager/desired_state.rb,如下:
def update(&block)
process_next_batch({}, Time.now, &block)
end而process_next_batch方法的实现如下:
def process_next_batch(bulk_token, start_time, &block)
with_credentials do |user, password|
options = {
:head => { 'authorization' => [user, password] },
:query => {
'batch_size' => batch_size,
'bulk_token' => encode_json(bulk_token)
},
}
if HealthManager::Config.black_box_test_mode?
res = make_synchronous_request(options)
bulk_token = process_response_and_get_next_bulk_token(res.code.to_i, res.body, start_time, &block)
process_next_batch(bulk_token, start_time, &block) unless bulk_token == nil
else
http = EM::HttpRequest.new(app_url).get(options)
http.callback do
bulk_token = process_response_and_get_next_bulk_token(http.response_header.status, http.response, start_time, &block)
process_next_batch(bulk_token, start_time, &block) unless bulk_token == nil
end
……………………
end
end
end实现过程如下:首先通过with_credentials方法获取user和password,然后通过这些credentials构建HTTP请求的body信息,最后通过Health_Manager的配置,来向Cloud Controller发送相应的HTTP请求,最终获取应用的预期运行状态,在process_response_and_get_next_bulk_token方法中实现,如下:
def process_response_and_get_next_bulk_token(status, raw_response, start_time, &block)
………………
batch.each do |app_id, droplet|
update_desired_stats_for_droplet(droplet)
@droplet_registry.get(app_id).set_desired_state(droplet)
block.call(app_id.to_s, droplet) if block
end
bulk_token
end3.4. Harmonizer模块源码实现
上文中提及到的Harmonizer模块是用于分析ActualState,得出如何将应用变成DisiredState的策略。
可以简单认为Harmonizer的任务有两个: 执行周期性的任务(比如定期获取DesiredState,分析应用状态等) 对一些消息做出反应(比如droplet.exit消息)
现在可以来看Harmonizer模块执行周期性任务的代码实现,首先进入Harmonizer的prepare方法:
def prepare
logger.debug { "harmonizer: #prepare" }
#schedule time-based actions
scheduler.immediately { update_desired_state }
scheduler.at_interval :request_queue do
nudger.deque_batch_of_requests
end
scheduler.at_interval :desired_state_update do
update_desired_state
end
scheduler.at_interval :droplets_analysis do
analyze_apps
end
scheduler.at_interval :droplet_gc do
gc_droplets
end
end可见,在Manager模块的start方法中@hamonizer.prepare实现就是调用以上的代码。分析代码可以获知其中通过scheduler对象来实现周期性调度。
通过scheduler的调度实现budger中分发队列中的请求,实现为nudger.deque_batch_of_request。
通过scheduler的调度实现DesiredState的周期性获取,实现为update_dedired_state。
通过scheduler的调度实现过期无用的应用的周期性GC,实现为gc_droplets。
通过scheduler的调度实现周期性分析应用状态的正确性,实现为analyze_app,该部分内容将着重讲述anaylze_apps的实现。
首先进入analyze_apps的代码实现:
def analyze_apps
unless desired_state.available?
logger.warn("Droplet analysis interrupted. Desired state is not available")
return
end
if @current_analysis_slice == 0
scheduler.set_start_time(:droplets_analysis)
logger.debug { "harmonizer: droplets_analysis" }
varz.reset_realtime!
end
droplets_analysis_for_slice
end进行简单的处理之后,该方法主要调用droplets_analysis_for_slice方法,实现如下:
def droplets_analysis_for_slice
droplets_analyzed_per_iteration = Config.get_param(:number_of_droplets_analyzed_per_analysis_iteration)
droplets = @droplet_registry.values.slice(@current_analysis_slice, droplets_analyzed_per_iteration)
if droplets && droplets.any?
droplets.each do |droplet|
analyze_droplet(droplet)
droplet.update_realtime_varz(varz)
end
end
@current_analysis_slice += droplets_analyzed_per_iteration
if droplets.nil? || droplets.size < droplets_analyzed_per_iteration
@current_analysis_slice = 0
finish_droplet_analysis
end
end分析的方式为找出@droplet_registry对象的每一个值,所谓一个应用,然后对这个应用的每一个实例进行分析,执行analyze_droplet方法,如下:
def analyze_droplet(droplet)
on_extra_app(droplet) if droplet.is_extra?
if droplet.has_missing_indices?
on_missing_instances(droplet)
droplet.reset_missing_indices
end
droplet.update_extra_instances
on_extra_instances(droplet, droplet.extra_instances)
droplet.prune_crashes
end实现过程中,首先判断该应用实例是否为多余的实例,若是执行on_extra_app方法;然后判断该应用实例是否存在多余的分片,若是执行on_missing_instances方法;接着对于该应用实例执行update_extra_instances方法,以及执行on_extra_instances方法和prune_crashes方法。关于这些方法的具体实现,在类Droplet中,主要是droplet出现不一致状态的判断以及修正。
以上分析analyze_apps是Harmonizer模块最重要的功能之一,但是除此之外,Harmonizer模块还会将处理一些其他的状态,比如:在ActualState模块接收到’droplet.exited’消息的时候,需要判断droplet退出的原因,然后根据原因,让Harmonizer做出相应的操作,源码如下:
case message.fetch(:reason)
when CRASHED
varz[:crashed_instances] += 1
droplet.process_exit_crash(message)
harmonizer.on_exit_crashed(droplet, message)
when DEA_SHUTDOWN, DEA_EVACUATION
droplet.reset_missing_indices
harmonizer.on_exit_dea(droplet, message)
when STOPPED
droplet.reset_missing_indices
harmonizer.on_exit_stopped(message)
end当退出的原因为DEA_SHUTDOWN和DEA_EVACUATION时,Harmonizer模块在on_exit_dea方法中会另外选择一个DEA来重启启动相应的应用;当退出的原因为STOPPED时,Harmonizer模块会在on_exit_stopped方法中,将droplet对象的状态改成相应的状态。
而在应用的状态为CRASHED时,Harmonizer在on_exit_crashed方法的处理过程会相当复杂,以下将一步一步分析其实现过程。
首先进入on_exit_crash方法中:
def on_exit_crashed(droplet, message)
logger.debug { "harmonizer: exit_crashed" }
index = message.fetch(:index)
instance = droplet.get_instance(message.fetch(:index), message.fetch(:version))
if instance.flapping?
execute_flapping_policy(droplet, instance, true)
else
nudger.start_instance(droplet, index, LOW_PRIORITY)
end
end可见在on_exit_crashed方法的实现中,从message对象中获取相应instance对象,随后判断该应用实例是否处于flapping状态,若是则执行execute_flapping_policy方法,若不是,则马上让nudger对象执行start_instance方法。
首先来简单阐述何为flapping状态。当一个应用的实例在flapping_timeout时间内已经崩溃超过flapping_death次数时,这个应用的实例会被认为是处于flapping状态。。以下是可能导致应用实例处于flapping状态的原因: 应用程序彻底损坏,导致不能启动; 应用程序中存在一个bug,导致应用每隔一段时间就会崩溃一次; 应用有一个外部依赖,比如说是CF-provisioned服务实例,然而该服务实例处于长时间的不可用状态,或者是暂时性的不可用状态,最终导致应用实例多次崩溃。
为了成功处理应用实例的flapping状态,Harmonizer提供以下策略: 计算出一个延迟,经过这个延迟时间后,立即重启这个应用实例; 对于之后的每次的崩溃,将以上的延迟时间翻倍,但不能超过max_restart_delay时间; 在计算延迟的时候,会加一个随机噪声,以避免连续的重启(关于噪声的意义,我还没有太理解,正在请教Pivotal的大牛) 当应用实例的崩溃次数超过giveup_crash_number,就放弃重启这个应用实例。
以下进入execute_flapping_policy方法:
def execute_flapping_policy(droplet, instance, chatty)
unless instance.pending_restart?
if instance.giveup_restarting?
logger.info { "given up on restarting: app_id=#{droplet.id} index=#{instance.index}" } if chatty
else
delay = calculate_delay(instance)
schedule_delayed_restart(droplet, instance, instance.index, delay)
end
end
end可以看到在实现过程中,会通过calculate_delay方法计算挤一个delay值,然后通过这个delay值去立即执行方法schedule_delayed_restart。
以下进入schedule_delayed_restart方法的代码实现:
def schedule_delayed_restart(droplet, instance, index, delay)
receipt = scheduler.after(delay) do
instance.unmark_pending_restart!
nudger.start_flapping_instance_immediately(droplet, index)
end
instance.mark_pending_restart_with_receipt!(receipt)
end可见在运行过程中,通过scheduler对象实现在delay这个时间段后,立即让nudger对象重启该实例对象。 以下是计算delay的方法实现:
def calculate_delay(instance)
delay = [interval(:max_restart_delay),
interval(:min_restart_delay) << (instance.crash_count - interval(:flapping_death) - 1)
].min.to_f
noise_amount = 2.0 * (rand - 0.5) * interval(:delay_time_noise).to_f
result = delay + noise_amount
logger.info("delay: #{delay} noise: #{noise_amount} result: #{result}")
result
end3.5. Nudger模块源码实现
Nudger模块是Health_Manager用来与Cloud Controller建立通信,并发送真正用来矫正应用状态的模块。
在实现过程中Nudger模块,通过分发cloudcontrollers.hm.request消息来通知Cloud Controller需要重启或者停止特定的应用实例。另外Nudger来维护了一个优先级队列来存储这部分的请求,实现优先级分发。
首先进入Nudger对于请求消息的分发实现:
def deque_batch_of_requests
@queue_batch_size.times do
break if @queue.empty?
request = @queue.remove
publish_request_message(
request[:operation],
request[:payload])
end
end首先从队列中取消一个请求,然后将请求通过publish_request_message方法发布出去,发布实现如下:
def publish_request_message(operation, payload)
logger.info("hm.nudger.request",
:operation => operation, :payload => payload)
if operation == 'start'
varz[:health_start_messages_sent]+=1
elsif operation == 'stop'
varz[:health_stop_messages_sent]+=1
end
publisher.publish("health.#{operation}", payload)
end在创建Nudger对象的时候,Message_bus被赋值于publisher,因此最终是通过消息中间件连接来实现消息的发布。
而在Nudger模块中还实现了start_flapping_instance_immediately方法,start_instance方法,start_instances方法,stop_instance_immediately方法,stop_instance方法,这些方法都是基于请求队列来实现,或者直接调用publish_request_message方法。
3.6. Reporter模块源码实现
Reports模块主要是为了对于”healthmanager.status”, ”healthmanager.health”, ”healthmanager.droplet”这一系列的请求。
Reports模块订阅这些主题消息的代码实现如下:
def prepare
@message_bus.subscribe('healthmanager.status') do |msg, reply_to|
process_status_message(msg, reply_to)
end
@message_bus.subscribe('healthmanager.health') do |msg, reply_to|
process_health_message(msg, reply_to)
end
@message_bus.subscribe('healthmanager.droplet') do |msg, reply_to|
process_droplet_message(msg, reply_to)
end
endprocess_status_message方法通过NATS给Cloud Controller返回某个droplet的状态;process_health_message方法通过NATS给Cloud Controller返回所有droplet的健康状态;process_droplet_message返回整个droplet的所有信息。
例如:当用户端执行cf apps指令时,Cloud Controller处即发布”healthmanager.health”消息,而Health_Manager通过Reports模块订阅该主题消息来响应该请求。
4. 总结
以上就是笔者对于HealthManager组件的源码分析。
相比Cloud Foundry v1中HealthManager组件的实现,HealthManager2.0 在架构设计上更为成熟。