浙江大学SEL实验室负责人,浙大SEL实验室创始人&带队老师,Cloud Native Computing Foundation会员。浙江省第一批青年科学家。《Docker容器与容器云》主要作者。设计建设国外高性能外汇交易系统、大型电商云平台,智慧城市云平台,具备丰富高性能分布式系统工程经验。



kubernetes+cilium原生路由(native routing)环境搭建
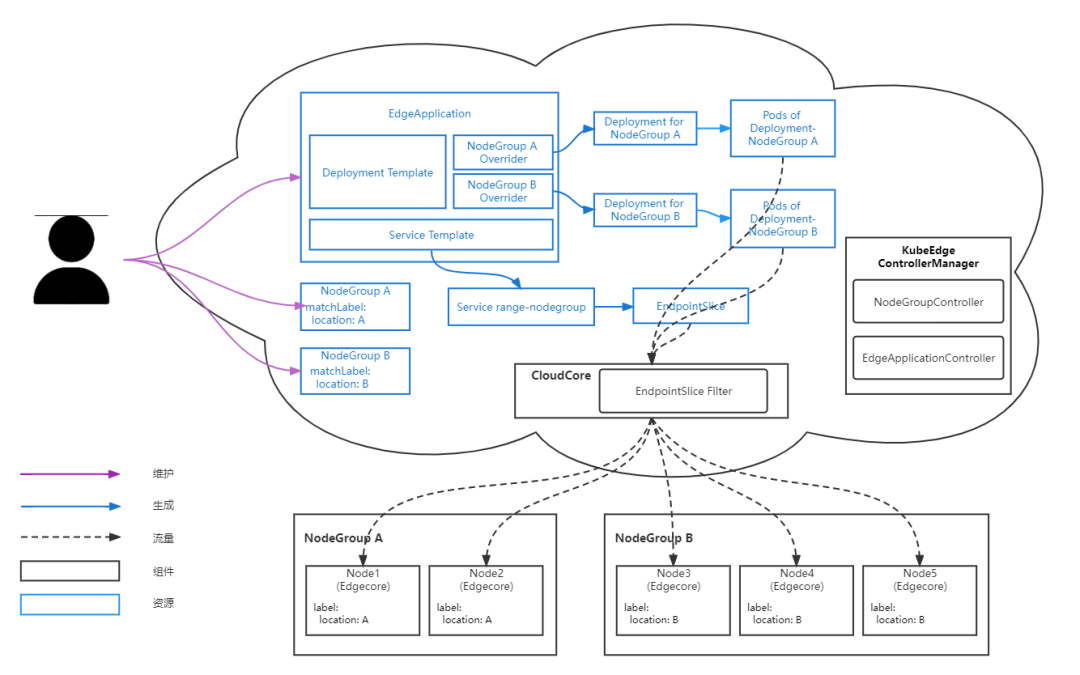
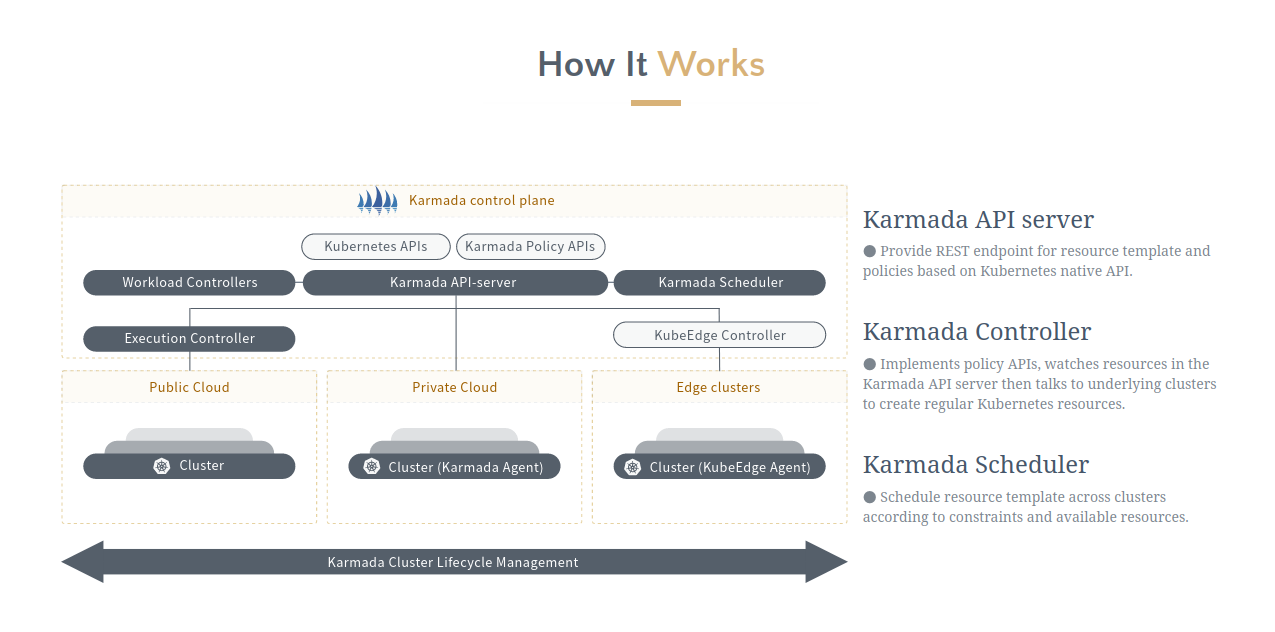
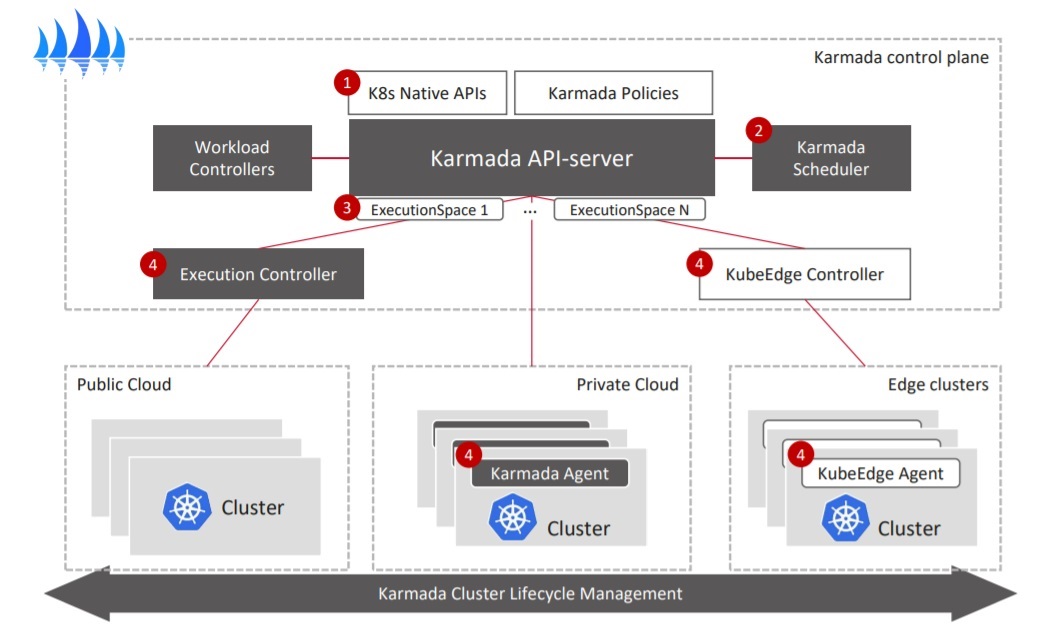
目前Cilium社区描述native routing搭建方法的资料较少,本文描述所有节点在同一个L2网络的情况下,kubernetes和cilium的原生路由安装以及配置方法。